Building an AutoTrader scraper with Python to search for multiple makes and models

Update November 2023: Please check out the new Autotrader scraper in the article How to scrape AutoTrader with Python and Selenium to search for multiple makes and models which uses Python, Selenium and RegEx.
Update September 2023: The Autotrader UK website has since changed their layout breaking this scraper, it last worked around June 2023 since I utilised it to find a used Honda Jazz! It seems HTML classes such as 'product-card-details__title' have been changed, making scraping more difficult. Thanks to everyone for your great feedback on this scraper, I will continue to try and find an alternative way or workaround and update the article if I find one 👍 Still lots to learn from this article!
Searching for used cars can be difficult and time consuming. AutoTrader is a great place to perform this search but as far as I can see, it does not allow to search for multiple makes and models in one search. Who wants to keep going back and forth between previously saved searchs, right? Wouldn't it be so much easier if you could compare all of them in one list?
Designing the solution
A solution would need to perform the following steps for each make and model given as inputs:
- Go to AutoTrader.
- Search for the given make and model with filters applied (price, year, mileage etc).
- Scrape information from each of the listings.
- Add the information to a list.
We can then output the information to CSV for further data analysis.
Finally, the CSV output can be formatted to make it easier to read and find the most optimal car even faster.
Installing required packages
This will rely on a few Python packages so if you are following along or are wanting to use this program yourself, install the following:
python -m pip install numpy pandas requests cloudscraper bs4 xlsxwriter openpyxl
Building the AutoTrader scraper
A good starting point in any project is asking 'has this been done before?' and 'is there existing open source code that can be used for this?'. Sometimes you want to code everything from scratch, and sometimes you want to get things done quickly. Building on the work of others is the foundation of computing and a testament to how far technology has come along in my view.
I found a very useful package called autotrader-scraper which used cloudscraper and beautifulsoup to scrape data from AutoTrader given some filter arguments. I extended this code to scrape the seller details and fixed an issue where the scraper retrieved the seller page link instead of the actual vehicle link from the HTML source.
import requests
import json
import csv
from bs4 import BeautifulSoup
import traceback
import cloudscraper
def get_cars(
make="BMW",
model="5 SERIES",
postcode="SW1A 0AA",
radius=1500,
min_year=1995,
max_year=1995,
include_writeoff="include",
max_attempts_per_page=5,
verbose=False):
# To bypass Cloudflare protection
scraper = cloudscraper.create_scraper()
# Basic variables
results = []
n_this_year_results = 0
url = "https://www.autotrader.co.uk/results-car-search"
keywords = {}
keywords["mileage"] = ["miles"]
keywords["BHP"] = ["BHP"]
keywords["transmission"] = ["Automatic", "Manual"]
keywords["fuel"] = [
"Petrol",
"Diesel",
"Electric",
"Hybrid – Diesel/Electric Plug-in",
"Hybrid – Petrol/Electric",
"Hybrid – Petrol/Electric Plug-in"
]
keywords["owners"] = ["owners"]
keywords["body"] = [
"Coupe",
"Convertible",
"Estate",
"Hatchback",
"MPV",
"Pickup",
"SUV",
"Saloon"
]
keywords["ULEZ"] = ["ULEZ"]
keywords["year"] = [" reg)"]
keywords["engine"] = ["engine"]
# Set up parameters for query to autotrader.co.uk
params = {
"sort": "relevance",
"postcode": postcode,
"radius": radius,
"make": make,
"model": model,
"search-results-price-type": "total-price",
"search-results-year": "select-year",
}
if (include_writeoff == "include"):
params["writeoff-categories"] = "on"
elif (include_writeoff == "exclude"):
params["exclude-writeoff-categories"] = "on"
elif (include_writeoff == "writeoff-only"):
params["only-writeoff-categories"] = "on"
year = min_year
page = 1
attempt = 1
try:
while year <= max_year:
params["year-from"] = year
params["year-to"] = year
params["page"] = page
r = scraper.get(url, params=params)
if verbose:
print("Year: ", year)
print("Page: ", page)
print("Response: ", r)
try:
if r.status_code != 200: # If not successful (e.g. due to bot protection)
attempt = attempt + 1 # Log as an attempt
if attempt <= max_attempts_per_page:
if verbose:
print("Exception. Starting attempt #", attempt, "and keeping at page #", page)
else:
page = page + 1
attempt = 1
if verbose:
print("Exception. All attempts exhausted for this page. Skipping to next page #", page)
else:
j = r.json()
s = BeautifulSoup(j["html"], features="html.parser")
articles = s.find_all("article", attrs={"data-standout-type":""})
# If no results or reached end of results...
if len(articles) == 0 or r.url[r.url.find("page=")+5:] != str(page):
if verbose:
print("Found total", n_this_year_results, "results for year", year, "across", page-1, "pages")
if year+1 <= max_year:
print("Moving on to year", year + 1)
print("---------------------------------")
# Increment year and reset relevant variables
year = year + 1
page = 1
attempt = 1
n_this_year_results = 0
else:
for article in articles:
car = {}
car["name"] = article.find("h3", {"class": "product-card-details__title"}).text.strip()
car["link"] = "https://www.autotrader.co.uk" + \
article.find("a", {"class": "listing-fpa-link"})["href"][: article.find("a", {"class": "listing-fpa-link"})["href"] \
.find("?")]
car["price"] = article.find("div", {"class": "product-card-pricing__price"}).text.strip()
seller_info = article.find("ul", {"class": "product-card-seller-info__specs"}).text.strip()
car["seller"] = " ".join(seller_info.split())
key_specs_bs_list = article.find("ul", {"class": "listing-key-specs"}).find_all("li")
for key_spec_bs_li in key_specs_bs_list:
key_spec_bs = key_spec_bs_li.text
if any(keyword in key_spec_bs for keyword in keywords["mileage"]):
car["mileage"] = int(key_spec_bs[:key_spec_bs.find(" miles")].replace(",",""))
elif any(keyword in key_spec_bs for keyword in keywords["BHP"]):
car["BHP"] = int(key_spec_bs[:key_spec_bs.find("BHP")])
elif any(keyword in key_spec_bs for keyword in keywords["transmission"]):
car["transmission"] = key_spec_bs
elif any(keyword in key_spec_bs for keyword in keywords["fuel"]):
car["fuel"] = key_spec_bs
elif any(keyword in key_spec_bs for keyword in keywords["owners"]):
car["owners"] = int(key_spec_bs[:key_spec_bs.find(" owners")])
elif any(keyword in key_spec_bs for keyword in keywords["body"]):
car["body"] = key_spec_bs
elif any(keyword in key_spec_bs for keyword in keywords["ULEZ"]):
car["ULEZ"] = key_spec_bs
elif any(keyword in key_spec_bs for keyword in keywords["year"]):
car["year"] = key_spec_bs
elif key_spec_bs[1] == "." and key_spec_bs[3] == "L":
car["engine"] = key_spec_bs
results.append(car)
n_this_year_results = n_this_year_results + 1
page = page + 1
attempt = 1
if verbose:
print("Car count: ", len(results))
print("---------------------------------")
except KeyboardInterrupt:
break
except:
traceback.print_exc()
attempt = attempt + 1
if attempt <= max_attempts_per_page:
if verbose:
print("Exception. Starting attempt #", attempt, "and keeping at page #", page)
else:
page = page + 1
attempt = 1
if verbose:
print("Exception. All attempts exhausted for this page. Skipping to next page #", page)
except KeyboardInterrupt:
pass
return results
This returns results from the get_car() function as a list. You can leave or edit the keywords inputs if you would like to pull back less or more results before filtering further.
Searching AutoTrader for multiple makes and models
Now we have a file named 'autotrader_scraper.py' we will create another file for the searcher which we'll name 'autotrader_searcher.py'.
This will use the get_car() function we created in the last step to retrieve information from AutoTrader for each make and model and then combine them into one list. This list can then be used to create a Pandas DataFrame for further filtering. In the criteria dictionary, be sure to replace the postcode with your postcode.
"""
Enables the automation of multiple autotrader searches.
Based on the autotrader-scraper package:
https://github.com/suhailidrees/autotrader_scraper
"""
from autotrader_scraper import get_cars
import pandas as pd
criteria = {
"postcode": "SW1A 0AA",
"min_year": 2008,
"max_year": 2014,
"radius": 40,
"min_price": 2000,
"max_price": 6000,
"fuel": "Petrol",
"transmission": "Manual",
"max_mileage": 100000,
"max_attempts_per_page": 3,
"verbose": False
}
civic = get_cars(
make = "Honda",
model = "Civic",
postcode = criteria["postcode"],
radius = criteria["radius"],
min_year = criteria["min_year"],
max_year = criteria["max_year"],
include_writeoff = "exclude",
max_attempts_per_page = criteria["max_attempts_per_page"],
verbose = criteria["verbose"]
)
print("Civic search done.")
jazz = get_cars(
make = "Honda",
model = "Jazz",
postcode=criteria["postcode"],
radius = criteria["radius"],
min_year = criteria["min_year"],
max_year = criteria["max_year"],
include_writeoff = "exclude",
max_attempts_per_page = criteria["max_attempts_per_page"],
verbose = criteria["verbose"]
)
print("Jazz search done.")
auris = get_cars(
make = "Toyota",
model = "Auris",
postcode=criteria["postcode"],
radius = criteria["radius"],
min_year = criteria["min_year"],
max_year = criteria["max_year"],
include_writeoff = "exclude",
max_attempts_per_page = criteria["max_attempts_per_page"],
verbose = criteria["verbose"]
)
print("Auris search done.")
corolla = get_cars(
make = "Toyota",
model = "Corolla",
postcode=criteria["postcode"],
radius = criteria["radius"],
min_year = 2000,
max_year = criteria["max_year"],
include_writeoff = "exclude",
max_attempts_per_page = criteria["max_attempts_per_page"],
verbose = criteria["verbose"]
)
print("Corolla search done.")
yaris = get_cars(
make = "Toyota",
model = "Yaris",
postcode=criteria["postcode"],
radius = criteria["radius"],
min_year = criteria["min_year"],
max_year = criteria["max_year"],
include_writeoff = "exclude",
max_attempts_per_page = criteria["max_attempts_per_page"],
verbose = criteria["verbose"]
)
print("Yaris search done.")
mazda3 = get_cars(
make="Mazda",
model="Mazda3",
postcode=criteria["postcode"],
radius=criteria["radius"],
min_year=criteria["min_year"],
max_year=criteria["max_year"],
include_writeoff="exclude",
max_attempts_per_page=criteria["max_attempts_per_page"],
verbose=criteria["verbose"]
)
print("Mazda3 search done.")
swift = get_cars(
make="Suzuki",
model="Swift",
postcode=criteria["postcode"],
radius=criteria["radius"],
min_year=criteria["min_year"],
max_year=criteria["max_year"],
include_writeoff="exclude",
max_attempts_per_page=criteria["max_attempts_per_page"],
verbose=criteria["verbose"]
)
print("Swift search done.")
results = (
civic +
jazz +
auris +
corolla +
yaris +
mazda3 +
swift
)
print(f"Found {len(results)} total results.")
df = pd.DataFrame.from_records(results)
df["price"] = df["price"] \
.str.replace("£", "") \
.str.replace(",", "") \
.astype(int)
df["distance"] = df["seller"].str.extract(r'(\d+ mile)', expand=False)
df["distance"] = df["distance"].str.replace(" mile", "")
df["distance"] = pd.to_numeric(df["distance"], errors="coerce").astype("Int64")
df["year"] = df["year"].str.replace(r"\s(\(\d\d reg\))", "", regex=True)
df["year"] = pd.to_numeric(df["year"], errors="coerce").astype("Int64")
shortlist = df[
(df["price"] >= criteria["min_price"]) &
(df["price"] <= criteria["max_price"]) &
(df["fuel"] == criteria["fuel"]) &
(df["mileage"] <= criteria["max_mileage"]) &
(df["transmission"] == criteria["transmission"]) &
(df["engine"] != "1.0L") &
(df["engine"] != "1.2L")
]
print(f"{len(shortlist)} cars met the criteria. Saving to 'autotrader-shortlist.csv'")
shortlist = shortlist.sort_values(by="distance")
shortlist.to_csv("autotrader-shortlist.csv")
As you can see from this code, when the time comes to replace my car I am determined to find a good condition, relatively low mileage, reliable Japanese car for less than £5000 that can get me from A to B without too many headaches! You might want to remove some of these cars and add others that are on your wish list.
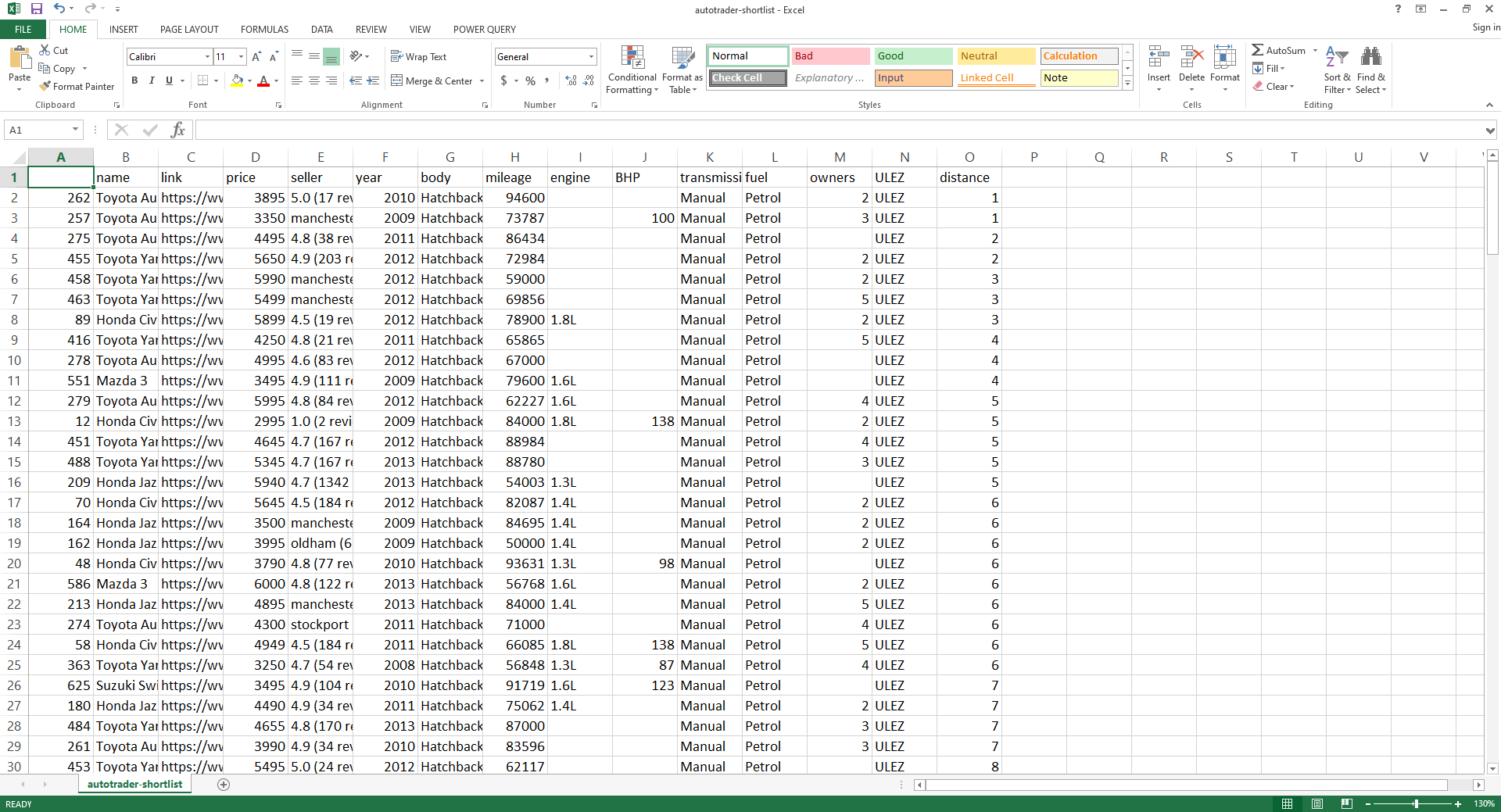
Formatting the shortlist
Now we have results returned from AutoTrader in CSV format, it would be nicer to apply some conditional formatting to this to quickly pick out the most viable vehicles - the hidden gems. Create another file named 'shortlist_formatter.py'.
import openpyxl
import numpy as np
import pandas as pd
import os
import shutil
import datetime
def format_autotrader_shortlist() -> None:
df = pd.read_csv("autotrader-shortlist.csv")
now = datetime.datetime.now()
df["miles_pa"] = df["mileage"] / (now.year - df["year"])
df["miles_pa"].fillna(0, inplace=True)
df["miles_pa"] = df["miles_pa"].astype(int)
most_viable_cars_mask = (
(df["mileage"] < 85000) &
(df["miles_pa"] < 9000) &
(df["owners"] <= 3)
)
df["viable"] = np.where(
most_viable_cars_mask,
"Y",
""
)
df = add_previously_viewed_cars(df)
df = df[[
"viable",
"viewed",
"name",
"link",
"price",
"year",
"mileage",
"miles_pa",
"owners",
"engine",
"seller",
"distance",
]]
writer = pd.ExcelWriter("autotrader-shortlist.xlsx", engine="xlsxwriter")
df.to_excel(writer, sheet_name="Sheet1", index=False)
workbook = writer.book
worksheet = writer.sheets["Sheet1"]
worksheet.conditional_format("E2:E1000", {
'type': '3_color_scale',
'min_color': '#63be7b',
'mid_color': '#ffdc81',
'max_color': '#f96a6c'
})
worksheet.conditional_format("F2:F1000", {
'type': '3_color_scale',
'min_color': '#f96a6c',
'mid_color': '#ffdc81',
'max_color': '#63be7b'
})
worksheet.conditional_format("G2:G1000", {
'type': '3_color_scale',
'min_color': '#63be7b',
'mid_color': '#ffdc81',
'max_color': '#f96a6c'
})
worksheet.conditional_format("H2:H1000", {
'type': '3_color_scale',
'min_color': '#63be7b',
'mid_color': '#ffdc81',
'max_color': '#f96a6c'
})
worksheet.conditional_format("I2:I1000", {
'type': '3_color_scale',
'min_color': '#63be7b',
'mid_color': '#ffdc81',
'max_color': '#f96a6c'
})
writer.save()
print("Shortlist formatting done.")
def add_previously_viewed_cars(df) -> pd.DataFrame:
df["viewed"] = ""
if not os.path.exists("Previous searches/Last search/autotrader-shortlist.xlsx"):
return df
viewed_cars = pd.read_excel(
"Previous searches/Last search/autotrader-shortlist.xlsx"
)
for index, row in df.iterrows():
car_in_previous_search = (
(viewed_cars["name"] == row["name"]) &
(viewed_cars["link"] == row["link"])
).any()
if car_in_previous_search:
df.loc[index, "viewed"] = "Y"
return df
def update_previous_search_history():
"""
Copies the autotrader shortlist Excel file to
'/Previous searches/Last search' to find cars
seen previously and to '/Previous searches'
for documenting historic searches.
"""
if not os.path.exists("autotrader-shortlist.xlsx"):
return
now = datetime.datetime.now()
date = f"{str(now.day)}-{now.strftime('%m')}-{str(now.year)}"
shutil.copyfile(
src="autotrader-shortlist.xlsx",
dst=f"Previous searches/autotrader-shortlist-{date}.xlsx"
)
shutil.copyfile(
src="autotrader-shortlist.xlsx",
dst=f"Previous searches/Last search/autotrader-shortlist.xlsx"
)
def open_file_in_excel() -> None:
os.system("start EXCEL.EXE autotrader-shortlist.xlsx")
if __name__ == "__main__":
format_autotrader_shortlist()
update_previous_search_history()
open_file_in_excel()
This calculates mileage per annum which is then used in a viability check. This means that the cars with the most potential are given a 'Y' in the viable column. Of course, even a car with relatively low mileage and a low number of previous owners can still be in a poor condition if it's not been looked after or has been sat idle for long periods of time, so this only highlights the potential gems. Using the most_viable_cars_mask identifies and marks cars as viable with a 'Y' which have less than 85000 miles, less than 9000 miles per annum and with 3 previous owners or less.
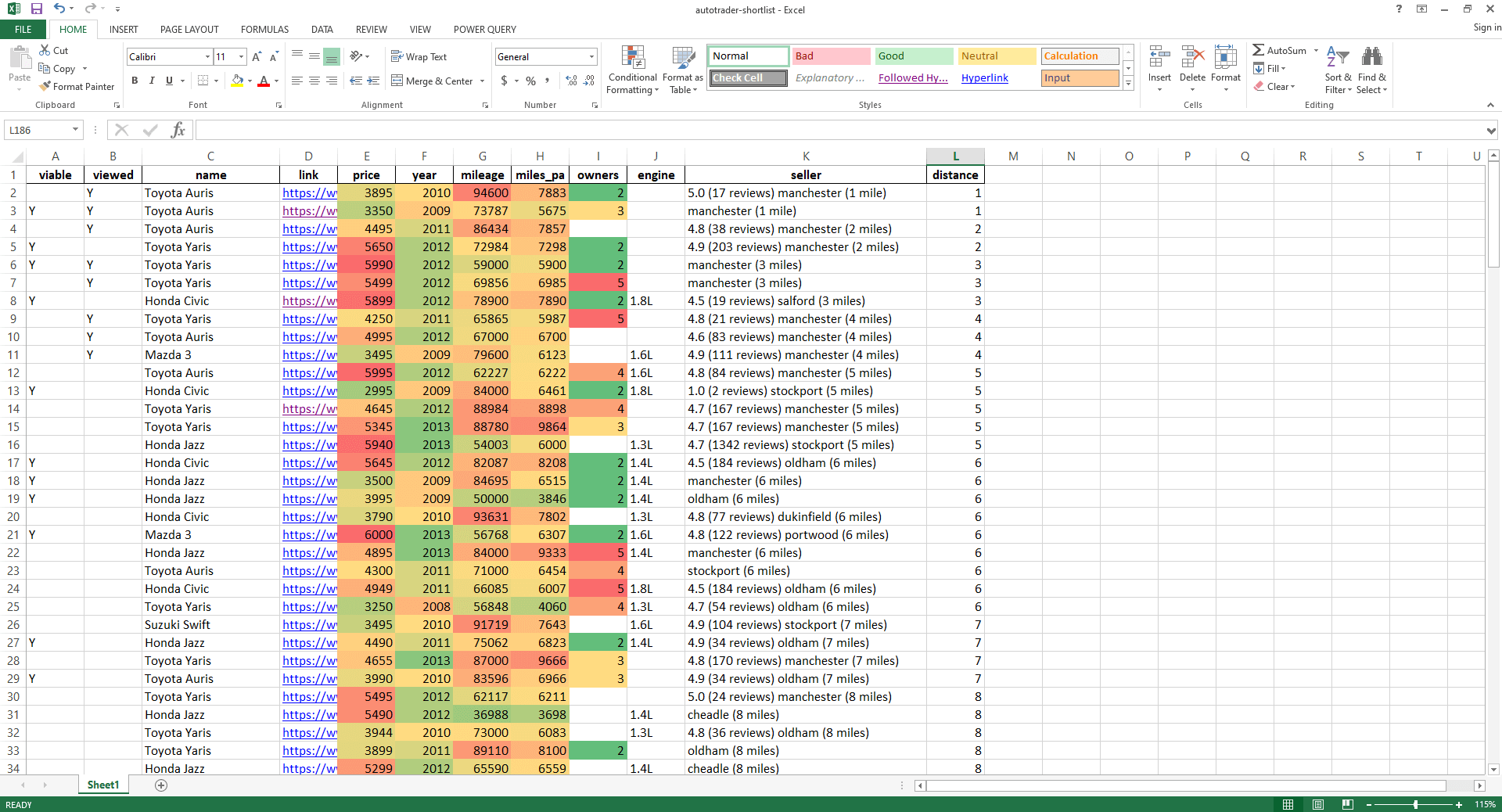
Taking it for a spin
Let's see the scraper, searcher, and formatter all in action one after another, in this end-to-end demo. I perform this process weekly to get the most up to date listing for my area. The formatter makes it really easy to see the trade offs in terms of price, year, mileage and previous owners.
Troubleshooting
On the odd occasion, the program does hang as it retries after a failed connection. The best way to correct this is to end the program using Ctrl + C, wait a short while, and then re-run it in a new console. This will establish a new connection and successfully return the results from the multiple scraping calls started by the get_cars() function.
Bonus: Identify cars seen in a previous search
As you might have noticed in shortlist-formatter.py after the formatting is complete, the autotrader search Excel file is copied to both the '/Previous searches' and '/Previous searches/Last search' folders with the update_previous_search_history function. This is so that on our next search we can cross-reference it with this historic data to find out if we've seen a particular car before! I found this to be an extremely useful addition especially if you are running this every week.
Finishing in first place
Spreading the search net wider to multiple makes and models and automating the search has been an excellent strategy for finding suitable cars within a reasonable distance from my location fast. I will update this section when I do go ahead a buy one to let you know what is was 😄 I am hoping my current car will last into next year, but at least I have this handy program ready to go if not.
The only thing left for you to do is set your criteria, add the makes and models you want, and off you go! Happy car hunting.
If you enjoyed this article be sure to check out other articles on the site.