Using PyPDF2 to score keywords in a job application

Introduction
AI and automated models will be used alongside human expertise more and more in the future. This article will explore a simple but useful example of this by counting and assessing keywords in job applications using Python. A model can bring a better quantitative assessment, whereas a human reviewer can bring a better qualitative assessment. Both are valuable.
What are the benefits?
I sit on interview panels to select and onboard apprentices, degree apprenticeships alongside junior and intermediate staff at a large organisation, for both the software / web development and the data science sides of the business. Managing this in combination with the day job, using AI and automation is super helpful. Sifting 100+ applicants can take many hours from many people.
It helps take a more objective approach and to be more critical. Did the candidate just load up on buzzwords without any real substance? Did the candidate use only a few target words but have solid examples that demonstrated the skills required? Did the candidate give solid examples which also included the target words? Which candidate would you invite to interview?
Understanding the PDF input
I can't share the individual job applications of course due to data protection, but I can share the model code and show what the outputs look like. You can then use this approach and tailor it to your specific needs.
The way that the organisation processes job applications means that only a single PDF is given to the panel with all of them combined. This enables anonymity and fairness in that you only see a candidate number and the application itself. No identifiable information given. It also meant that the model would first need to separate this large PDF file into the constituate applications. You will see in the code, I achieved this by splitting the text of the file on 'Application ID:'.
This is what the large PDF file looked like. I have censored all text for privacy.
If your situation requires many files instead of just one that requires splitting up, you can adapt this code using the approach found in Searching for text in PDFs at increasing scale.
Creating the model
Before taking a look at the model, here is a brief summary of what's going on:
- We define essential and desirable
criteriakeywords to look for. - We then use PyPDF2 to
read_applicationsfrom the PDF using the filepath to it. - After splitting the text into separate applications we then
score_applicationsusing regex to count keyword matches. - Finally, we use
scores.describe()to provide summary statistics.
# -*- coding: utf-8 -*-
"""
A scoring model to help with job application sifting.
Enter keywords for the role essential and desirable criteria, then run the program.
The outputs will be saved in the 'applications', 'scores' and 'statistics' variables.
Documentation for PyPDF2: https://pypdf2.readthedocs.io/en/3.0.0/
Migration guide for PyPDF2: https://pypdf2.readthedocs.io/en/3.0.0/user/migration-1-to-2.html
"""
import re
import time
import PyPDF2
import pandas as pd
def criteria():
return {
"essential": [
"maths",
"a level",
"numeric",
"analytical",
"technologi",
"language",
"data",
"business challenge",
"problem solving",
"communicat"
],
"desirable": [
"programming skills",
"analysis",
"data manipulation",
"analytical software",
"software packages",
"RStudio",
"SQL",
"Power BI",
"Excel",
"mathematical models",
"infrastructure",
"security",
"web design",
"agile",
"agile project methodology",
"customer facing",
"technical and non-technical",
"data architecture",
"innovative"
]
}
def read_applications(filepath: str) -> list:
pdf_reader = PyPDF2.PdfReader(filepath) # Formerly PyPDF2.PdfFileReader(filepath)
number_of_pages = pdf_reader.getNumPages()
all_text = ""
for i in range(0, number_of_pages):
pages = pdf_reader.pages[i] # Formerly reader.getPage(pageNumber)
text = pages.extractText()
all_text += text
applications = all_text.split("Application ID:")
return applications
def score_applications(applications: list, criteria: dict):
scores = []
for application in applications:
score = {
"application_id": application[1:8],
"word_count": 0,
"essential": 0,
"desirable": 0,
"matched_terms": ""
}
for term in criteria["essential"]:
if re.search(term, application):
print(f"Matched '{term}' in application {score['application_id']}")
score["essential"] += 1
score["matched_terms"] += (term + " ")
for term in criteria["desirable"]:
if re.search(term, application):
print(f"Matched '{term}' in application {score['application_id']}")
score["desirable"] += 1
score["matched_terms"] += (term + " ")
score["word_count"] = len(application.split())
scores.append([
score["application_id"],
score["word_count"],
score["essential"],
score["desirable"],
score["essential"] + score["desirable"],
score["matched_terms"]
])
columns = ["Application ID", "Word Count", "Essential",
"Desirable", "Combined", "Matched Terms"]
return pd.DataFrame(scores, columns=columns)
if __name__ == "__main__":
start = time.time()
applications = read_applications("C:\\Users\\shedloadofcode\\OneDrive\\Documents\\Recruitment\\Recruitment Jan 2023\\Applications\\applications for sift (109).pdf")
scores = score_applications(applications, criteria())
statistics = scores.describe()
print(f"Bot finished in {round(time.time() - start, 2)} seconds")
I created the model using Spyder IDE and the key variables are then stored as outputs in the variable explorer - the top right window.
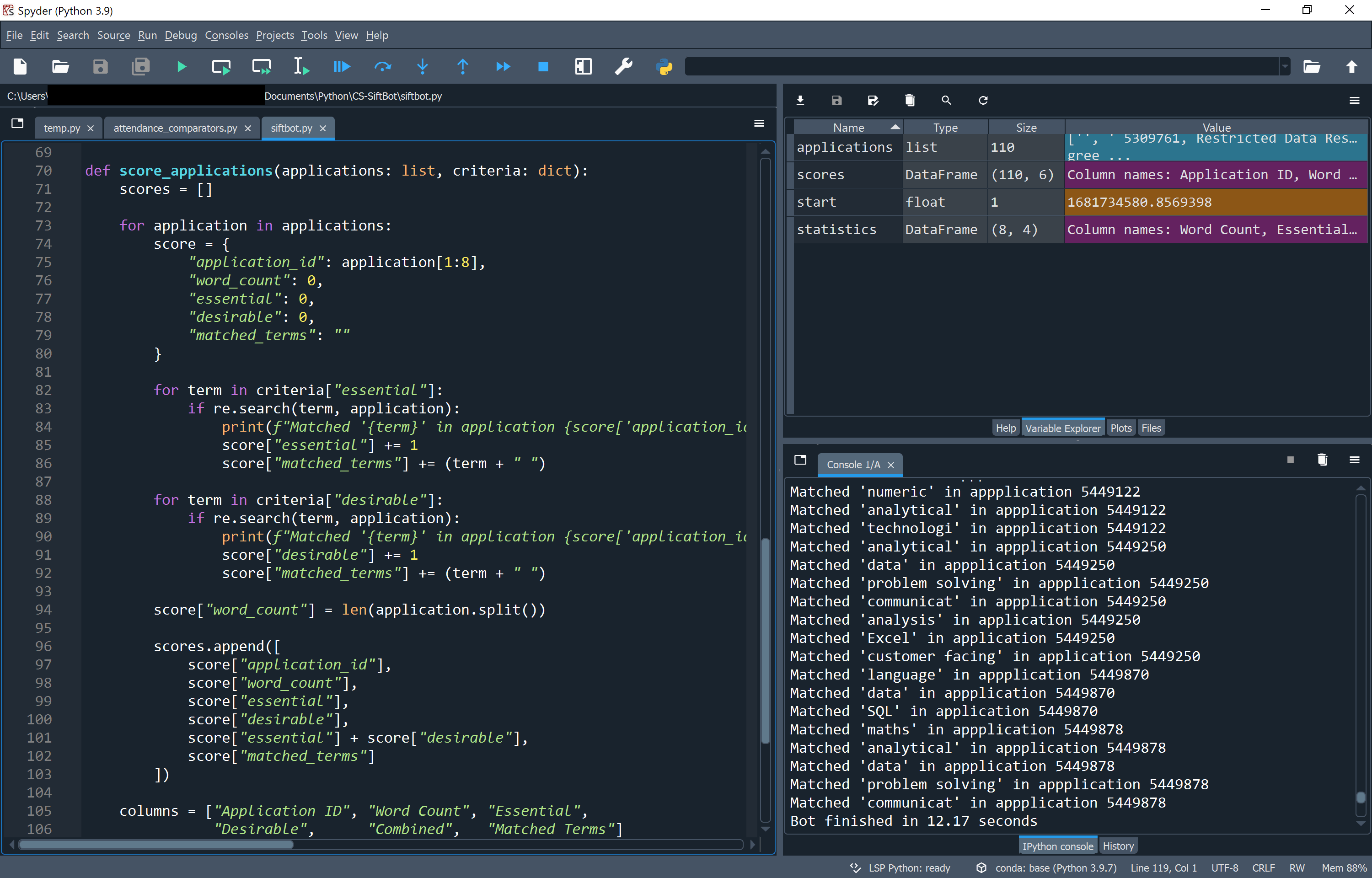
Viewing the outputs
Using the variable explorer the outputs can be analysed. We can first sense check that all of the applications were split up correctly on 'Application ID:' and that there are 109 records as expected in applications.

The results of the scoring is shown in scores which is super helpful by providing an application word count, a count of essential and desirable keywords matched, a combined count, and the matched terms themselves.
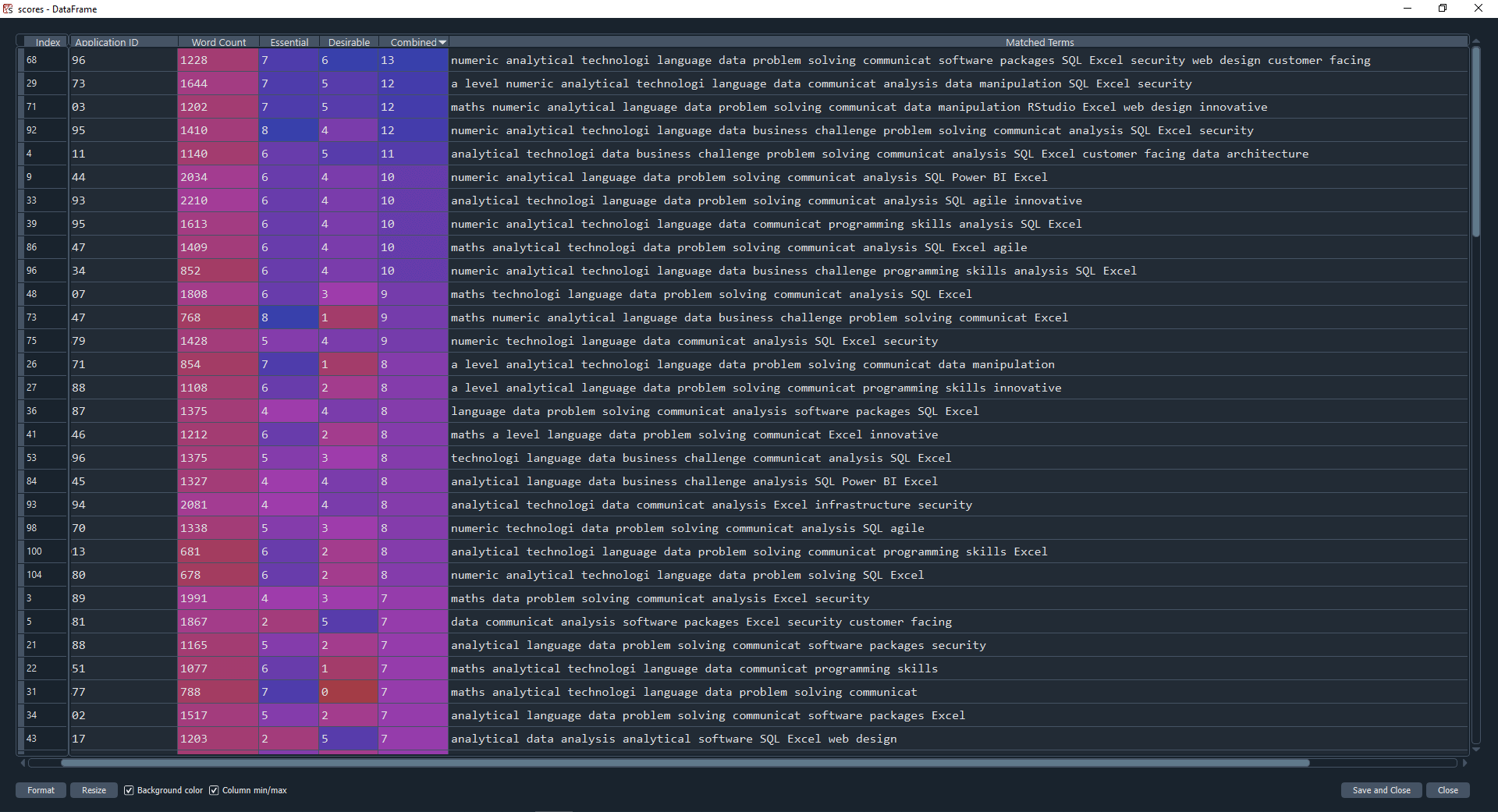
This means you can sort by essential, desirable or total keywords matched. It also opens up further insights, such as 'did a candidate have a high word count, but didn't use many keywords?'.
To aid with these kinds of questions, we can view the statistics output to find out min, max, mean and median (50%) word counts, essential, desirable and combined counts. This helps us to assess how a particular candidate compares to the average in terms of word count vs matched terms.
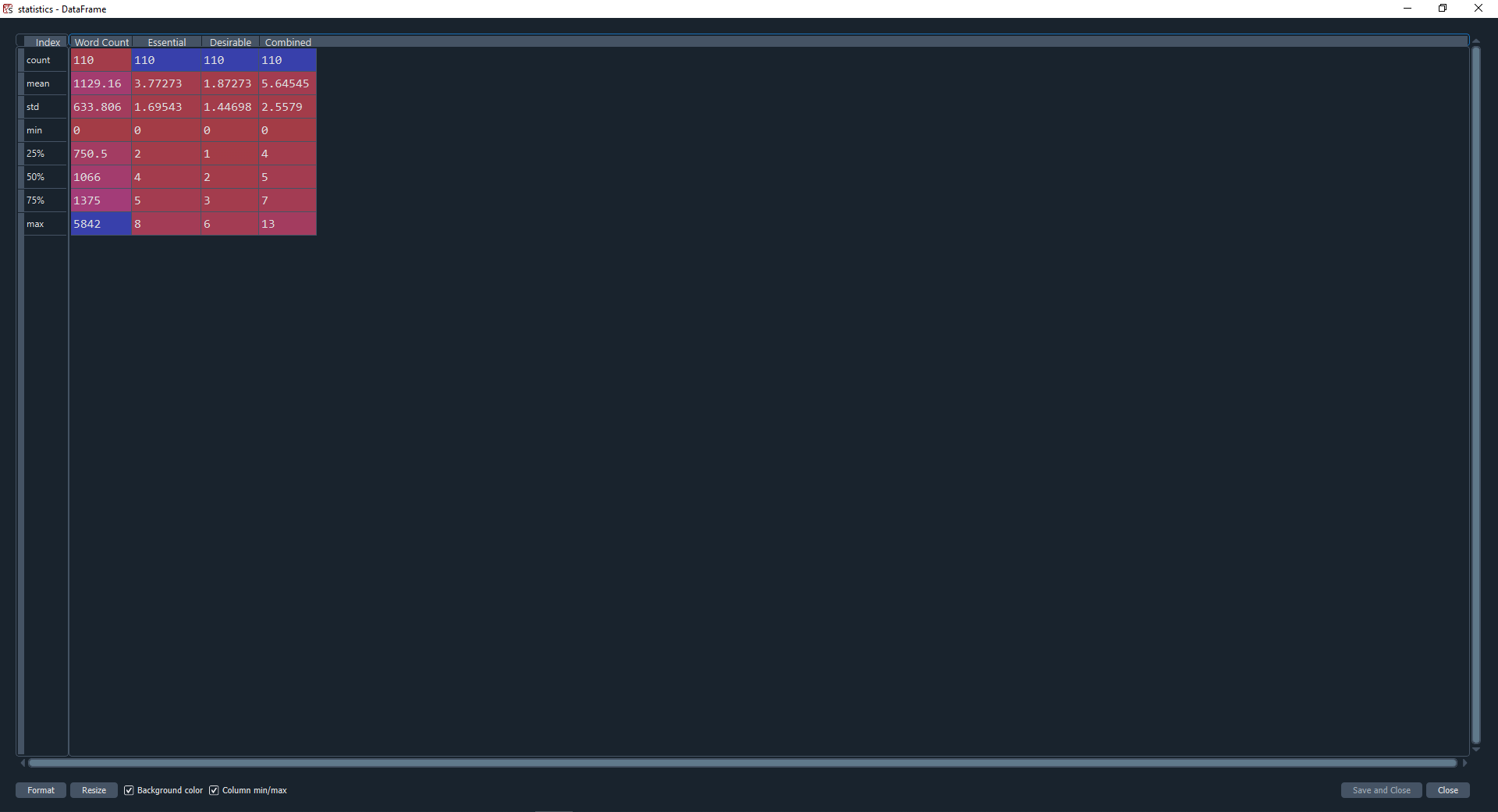
The scores DataFrame could also be saved to a CSV file to share with other panel members.
Final thoughts and interactive tool
Thanks for reading 😄 I hope you found this article interesting.
I used the logic from the code in this article to create an interactive JavaScript tool Job Application Keyword Checker. Be sure to check it out and give it a go, you can get started by hitting 'Show me an example' and take it from there!
My final thought is that we should never blindly trust a model, especially in cases such as these where we are assessing suitability for a job position. A quantitative model can only get us so far. We should always carry out a human review and ask critical questions such as:
- Is the candidate strong even though they didn't directly match many keywords?
- Did the candidate just drop all the keywords into their application without really understanding them?
This ensures fairness and avoids simple keyword matching bias, whilst also allowing the model to aid in decision making and speed up reviews.
As always, if you enjoyed this article, be sure to check out other articles on the site.



